网络边缘涉及一类产品,从汽车和无人机到安全摄像机,智能扬声器甚至企业服务器。所有这些应用程序都包含运行机器学习算法的低功耗芯片。尽管这些芯片与其他数字芯片具有许多相同的组件,但主要区别在于大部分处理都在内存中或附近进行。
考虑到这一点,AI边缘芯片的代工厂商正在为其下一代设备评估不同类型的存储器。每个挑战都有其自身的挑战。此外,尽管芯片在许多情况下使用的是成熟工艺而不是最先进的节点,但它们本身也必须采用低功耗架构。
AI芯片:有时称为深度学习加速器或处理器。经过优化,可以使用机器学习来处理系统中的各种工作负载。机器学习是AI的子集,它利用神经网络处理数据并识别模式。它匹配某些模式,并了解其中哪些属性很重要。
这些芯片面向整个计算应用领域,但是这些设计存在明显的差异。例如,为云开发的芯片通常基于高级流程,并且设计和制造成本很高。同时,边缘设备包括为汽车市场开发的芯片,以及无人机,监控摄像头,智能手机,智能门铃和语音助手。在这一广泛的领域中,每个应用程序都有不同的要求。例如,智能手机芯片与为门铃创建的芯片根本不同。
对于许多边缘产品,目标是开发具有足够计算能力的低功耗设备。
“这里买不起300瓦的GPU。对于许多这类应用程序来说,即使是30瓦的GPU也太高了,” The Linley Group首席分析师Linley Gwennap表示。“但是设备制造商仍然希望做一些复杂的事情。这需要比微控制器更多的AI功能。您需要功能强大的东西,但又不会耗尽电池或耗尽钱包,尤其是在消费类应用程序中。因此,您必须考虑一些相当激进的新解决方案。”
一方面,大多数边缘设备不需要高级节点上的芯片,因为它们太昂贵了。当然也有例外。此外,许多AI边缘芯片可处理内存中或内存附近的处理功能,从而以更少的功耗加速了系统。
供应商正在采用各种内存方法,并正在为将来的芯片探索新的方法。例如:
* 使用SRAM等常规存储器。
* 将NOR闪存用于一种称为模拟内存计算的较新技术。
* 利用相变存储器,MRAM,ReRAM和其他下一代存储器,这些存储器正在开发用于AI边缘芯片。
机器学习已经存在了数十年。但是,多年来,系统没有足够的能力来运行这些算法。近年来,由于GPU和其他芯片的出现以及机器生成的算法的出现,机器学习开始蓬勃发展。这些设备和其他设备的目标是在神经网络中处理算法,该算法计算矩阵乘积和总和。数据矩阵被加载到网络中。然后,将每个元素乘以预定的权重,并将结果传递到网络的下一层,并乘以一组新的权重。经过几个这样的步骤,结果就是有关数据的结论。机器学习已经在许多行业中部署,并且在半导体行业中,已经出现了数十个机器学习芯片供应商。许多都是为云计算开发的芯片。在系统中,这些芯片旨在加速Web搜索,语言翻译以及其他应用程序。根据Linley Group的数据,2019年这些设备的市场规模超过30亿美元。
还出现了数十个AI边缘芯片供应商,例如Ambient,BrainChip,GreenWaves,Flex Logix,Mythic,Syntiant等。该公司表示,到2024年,预计总共将有16亿台边缘设备配备深度学习加速器。AI边缘芯片还使用8位计算来运行机器学习算法。“您想在生成和使用数据的地方进行处理。这里有一些巨大的优势。当我们开始时,它是关于电池寿命的。如果不打开与Internet的连接,而可以在本地进行AI,则可以节省大量电量。响应性和可靠性同样重要,可靠性也至关重要,最终也要保证隐私。” Syntiant首席执行官Kurt Busch说。“在深度学习中,这还与内存访问有关。您的能力以及性能瓶颈都与内存有关。其次,它也是并行处理。在深度学习中,我可以并行进行数百万次乘法和累加,并通过并行处理有效地线性缩放。”AI边缘芯片有不同的要求。例如,智能手机采用了先进的应用处理器。但这对于其他边缘产品(如门铃,监控摄像头和扬声器)而言并非如此。“对于针对边缘的解决方案,涉及经济问题。它必须对成本敏感。整体目的是要具有竞争力的成本,低功耗和简化的计算分布,” UMC业务发展副总裁Walter Ng表示。还有其他考虑。许多AI边缘芯片供应商都在40nm左右的成熟节点上交付产品。这一过程很便宜,因此在一个层面上是理想的。但展望未来,供应商希望以低功耗获得更高的性能。下一个节点是28nm,这也是成熟且便宜的。最近,代工厂商推出了各种22nm工艺,这是28nm的扩展。22nm比28nm快一点,但是价格更高。大多数供应商不会迁移到16nm / 14nm的finFET,因为它太贵了。移至下一个节点不是一个简单的决定。Ng说:“今天,许多客户及其应用都在40nm上。” “当他们着眼于下一个节点路线图时,他们是否会感到满意并在28nm上获得最佳性价比?还是22nm看起来比28nm更具吸引力并提供更多好处?这是许多人正在考虑的考虑因素。”
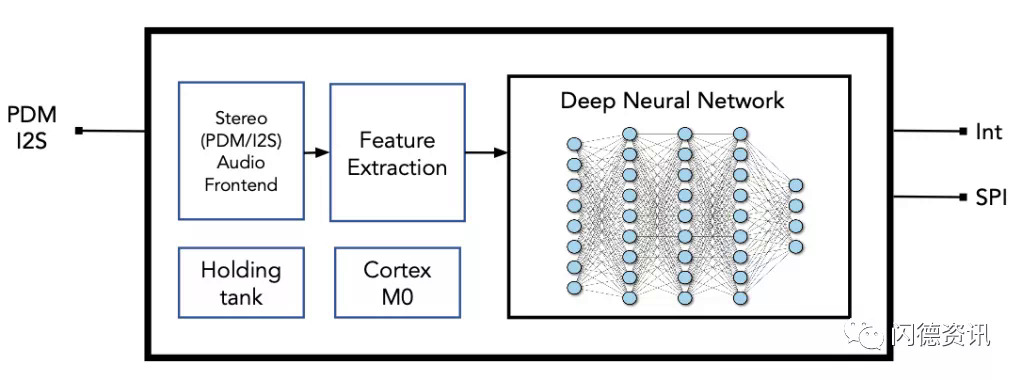
还有其他注意事项。在传统系统中,内存层次结构很简单。为此,将SRAM集成到用于高速缓存的处理器中,该高速缓存可以访问常用程序。DRAM用于主内存,是独立的,位于内存模块中。在大多数系统中,数据在内存和处理器之间移动。但是这种交换会导致等待时间和功耗的增加,这有时被称为内存墙,并且随着数据量的增加而变得越来越成问题。并非所有芯片都使用内存计算。但是,AI边缘芯片供应商正在使用这些方法来帮助打破内存壁。他们还从云上转移了一些处理功能。例如,去年,Syntiant推出了其第一款产品“神经决策处理器”,该神经决策处理器将神经网络体系结构集成到了一个小巧的低功耗芯片中。40nm音频设备还集成了具有112KB RAM的Arm Cortex-M0处理器。图1:Syntiant的NDP100音频神经决策处理器来源:SyntiantSyntiant使用基于SRAM的内存,将其体系结构归类为近内存计算。芯片背后的想法是使语音成为系统中的主要接口。亚马逊的Alexa是始终在线语音界面的一个示例。展望未来,Syntiant正在开发新设备,并正在研究不同的存储器类型。Syntiant首席科学家Jeremy Holleman说:“我们正在研究一些新兴的内存技术,例如MRAM和ReRAM,主要是为了提高密度。” “读取功率然后闲置功率也是一件大事,因为对于大型模型,您最终拥有很多内存。但是,也许您只是在给定实例上对相当小的子集进行计算。不使用存储单元时,降低其功耗的能力至关重要。”目前不需要高级流程。Syntiant的Busch说:“在可预见的将来,先进节点的泄漏对于超低功耗应用来说太高了。” “边缘设备经常无所作为。与数据中心中的设备相反,他们已经开机并等待发生某些事情。您希望它一直在做某事。边缘设备经常在等待某些事情发生。因此,您需要非常低的功耗,而高级节点并不擅长于此。”
有一些问题。如今,大多数AI芯片都依赖内置的SRAM,速度很快。赛普拉斯IP业务部设计总监Vineet Kumar Agrawal说:“但是,无论采用哪种技术,使用SRAM在独立的数字边缘处理器中安装数百万的重量都是非常昂贵的。” “从DRAM获取数据的成本比从内部SRAM获取数据的成本高500倍。”
同时,许多AI边缘芯片供应商正在使用或寻找另一种内存类型-NOR。NOR,一种非易失性闪存,用于独立和嵌入式应用程序中。NOR通常用于代码存储。NOR成熟且健壮,但是在每个节点上都需要额外且昂贵的屏蔽步骤。而且很难将NOR扩展到28nm / 22nm以上。尽管如此,使用当今的NOR闪存,一些公司正在开发一种称为模拟内存计算的技术。这些设备大多数是从40nm节点开始的。内存模拟有望降低功耗。但是,并非所有的NOR都是一样的。例如,某些NOR技术基于浮栅架构。Microchip使用基于NOR的浮门方法,开发了一种用于机器学习的模拟内存计算架构。该技术集成了乘法累加(MAC)处理引擎。“通过这种方法,用户无需将模型参数或权重存储在SRAM或外部DRAM中,” Microchip SST部门嵌入式存储器产品开发总监Vipin Tiwari说。“将输入数据提供给阵列以进行MAC计算。由于计算是在存储权重的地方完成的,因此消除了MAC计算中的存储瓶颈。”还有其他NOR选项。例如,赛普拉斯一段时间以来一直在提供另一种称为SONOS的嵌入式NOR闪存技术。SONOS基于电荷陷阱闪存,是一种双晶体管技术。可通过从氮化物层添加或去除电荷来改变阈值电压。它可用于最小28nm的各种节点。SONOS可以优化为机器学习的嵌入式存储器。“两个SONOS多位嵌入式非易失性存储单元最多可以替代8个SRAM单元,即48个晶体管。这里有面积效率。赛普拉斯的Agrawal说:“您还可以将功率效率和吞吐量提高50到100倍。” “ SONOS使用高度线性和低功率的隧穿过程进行编程,该过程能够通过高度控制来瞄准Vts,从而产生纳安级比特单元电流水平。这与使用热电子的浮栅相反,在浮栅中您无法控制流入电池的电流量。另外,您的电池电流要高得多。”
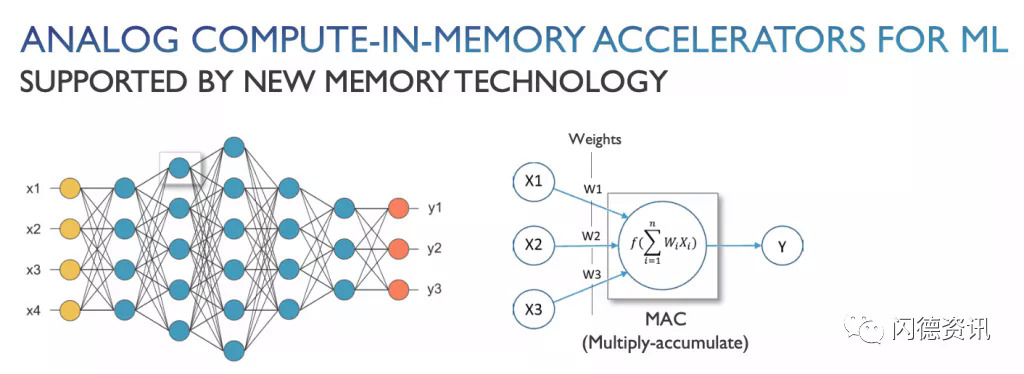
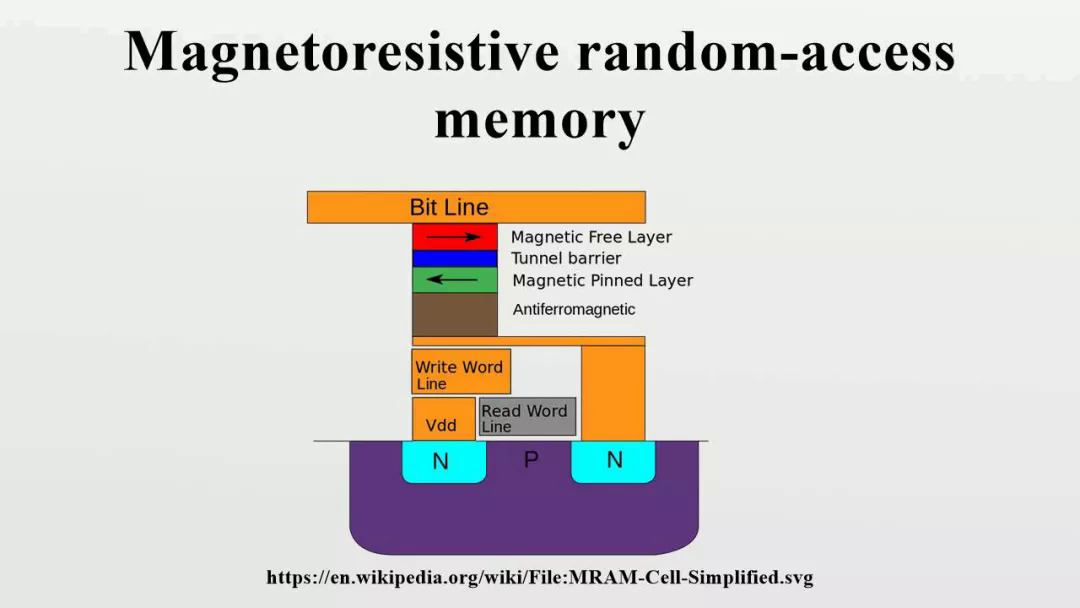
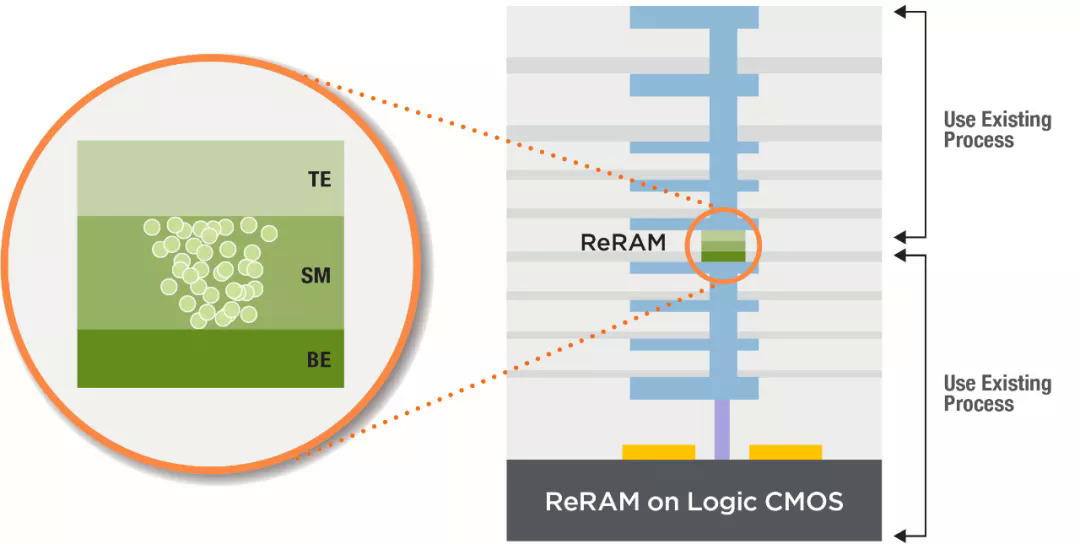
但由于NOR无法扩展到28nm / 22nm以上,因此AI边缘芯片供应商正在研究几种下一代存储器类型,例如相变存储器(PCM),STT-MRAM,ReRAM等。对于AI而言,这些记忆还运行带有神经网络的机器学习应用程序。图2:使用新内存的ML模拟内存计算加速器来源:Imec这些存储器类型具有吸引力,因为它们将SRAM的速度和闪存的非易失性结合在一起,具有无限的耐久性。但是新的存储器需要花费更长的时间开发,因为它们使用复杂的材料和切换方案来存储数据。“半导体制造商在从基于电荷的存储器(SRAM,NOR)迁移到电阻性存储器(ReRAM,PCM)时面临新的挑战,” KLA过程控制解决方案亚洲地区总监Masami Aoki说。“这些新兴的存储器由新元素组成,需要精确控制材料性能和新的缺陷控制策略,以确保性能均匀性和可靠性,特别是对于大规模集成而言。”不过,一段时间以来,英特尔一直在发售3D XPoint,这是一种PCM。镁光公司还出售PCM。非易失性存储器PCM通过更改材料的状态来存储数据。它比具有更好耐久性的闪光灯更快。PCM是一项具有挑战性的技术,尽管供应商已解决了这些问题。Lam Research执行副总裁兼首席技术官Rick Gottscho表示:“凭借相变存储器3D XPoint,硫属元素化物对环境条件和过程化学非常敏感。“有各种各样的技术策略可以处理所有这些问题。”PCM也是AI的目标。2018年,IBM发表了一篇关于使用PCM的8位精度内存乘法技术的论文。尽管没有人批量销售产品,但IBM和其他公司仍在为AI边缘应用程序开发PCM。STT-MRAM也在出货。它具有SRAM的速度和闪存的非易失性以及无限的耐用性。它利用电子自旋的磁性在芯片中提供非易失性。STT-MRAM是嵌入式应用的理想选择,该应用旨在取代22nm及以上的NOR。“如果您查看新的内存,MRAM是低密度(小于1吉比特)的最佳选择。MRAM是最好的嵌入式内存。即使您可以在28nm或更大的那一代进行NOR,它也比NOR更好。NOR添加了12个以上的蒙版,因此基于成本,密度和性能,MRAM是嵌入式的首选选项。” MKW Ventures Consulting负责人Mark Webb说。但是,MRAM仅支持两个级别,因此不适合于内存中计算。其他人则有不同的看法。Imec的杰出技术人员Diederik Verkest说:“一个MRAM设备实际上只能存储一个位。” “但是,在内存计算中,重要的是要了解存储设备和计算单元之间的差异。计算单元执行存储的权重和输入激活的乘法。在最佳情况下,计算单元内部的存储设备可以存储多个重量级别。但是,可以使用多个存储设备制作存储权重的计算单元。如果使用3级权重(则权重可以为-1、0、1),然后可以使用两个存储设备,并且计算单元将由两个存储设备以及周围的一些模拟电路组成,以计算重量值与激活值的乘积。因此,MRAM设备可以在计算单元内部使用,以存储多级权重并构建内存计算解决方案。”ReRAM是另一种选择。与闪存相比,该技术具有更低的读取延迟和更快的写入性能。在ReRAM中,将电压施加到材料堆栈上,从而导致电阻变化,从而将数据记录在内存中。在最近的IEDM会议上,Leti介绍了一篇有关使用模拟和ReRAM技术开发集成尖峰神经网络(SNN)芯片的论文。130nm测试芯片的每个峰值功耗为3.6pJ。正在研发使用28nm FD-SOI的设备。SNN与传统的神经网络不同。Linley Group的Gwennap说:“直到输入改变,它才使用任何电源。” “因此,从理论上讲,如果您有安全摄像头并且正对着您的前院看,那是理想的选择。直到有人走过去,一切都不会改变。”Leti的SNN设备是边缘的理想选择。Leti的研究工程师Alexandre Valentian说:“边缘到底是什么意思,还有待观察,但我可以指出,ReRAM和SNN特别针对端点设备而定制。” “ ReRAM和峰值编码非常适合,因为这种编码策略简化了内存中的计算。不需要在输入端使用DAC(就像在矩阵矢量乘法中一样),它可以简化输出端的ADC(位数更少),或者如果神经元是模拟的,则最终将其完全删除。”但是,ReRAM很难开发。只有少数几个已装运零件。“我们和其他人都证明ReRAM在1T1R设计(嵌入式)和将来使用合适的交叉点选择器的1TnR方面具有出色的理论。挑战在于过去两年中实际产品的缓慢开发。我们认为,这是由于存储元素本身的保留和干扰以及循环问题所引起的。这些问题需要解决,我们需要具有64Mbit嵌入式和1Gbit交叉点的实际产品。” MKW的Webb说。总而言之,哪种下一代内存类型适用于AI Edge应用尚无共识。业界继续探索当前和未来的选择。例如,Imec最近评估了几种选择,以使用称为AiMC的模拟内存计算架构启用10000TOPS / W矩阵矢量乘法器。Imec评估了三个选项-SOT-MRAM;IGZO DRAM; 和投影PCM。自旋轨道扭矩MRAM(SOT-MRAM)是下一代MRAM。铟镓锌氧化物(IGZO)是一种新颖的晶体形态。可以使用多个设备选项来存储DNN的权重。Imec的Verkest表示,列出的设备使用不同的机制来存储重量值(磁性,电阻,电容),并导致AiMC阵列的不同实现。目前尚不清楚哪种当前或未来的下一代内存技术是赢家。也许所有技术都有一个地方,SRAM,NOR和其他常规存储器也占有一席之地。
点击此处关注,获取最新资讯!


















































我的评论
最新评论