据闪德资讯获悉,AI的发展正经历一次重要转折,正从训练主导,转向推理主导。
随着ChatGPT、Sora等AI应用进入日常生活,AI运算需求的核心已从一次性的模型训练,转向持续高频发生的模型推理。
这场转变,不仅在催生专用AI推理芯片,更在存储领域引发了一场以“总拥有成本(TCO)”为核心的架构变革。
AI技术的需求差异化
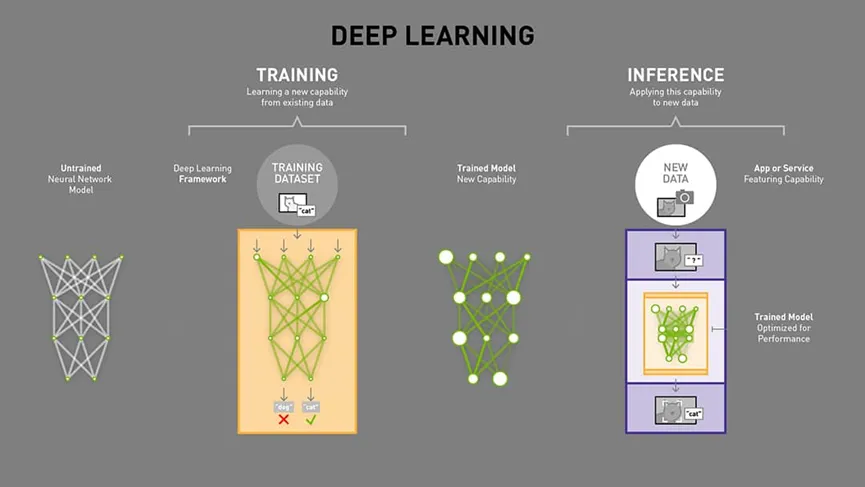
在深度学习领域,模型训练与模型推理是两个截然不同的阶段,对GPU和存储的需求也大相径庭。
模型训练是典型的计算密集型任务,需要极高的浮点运算能力与高带宽内存。
训练过程中,系统不仅要存储完整的模型参数,还需要大量GPU存储来存储中间激活值、参数梯度和优化器状态。
举例来说,一个拥有10亿参数的模型,FP32权重约为4GB,加上梯度、优化器状态和激活值,总存储需求可能达到20-30GB甚至更多。
训练阶段通常使用精度高的FP32或混合FP16/BF16格式,并需要HBM支持。
相比之下,模型推理阶段,特别是长上下文任务,虽然也需要内存带宽,但更侧重于快速存取大量模型参数。
推理是按需、实时的,完全由用户行为驱动,不像训练时那样可预测、重复,反而更加复杂且难以优化。
AI推理引发存储需求暴增
业界有个精准的描述“推理等于IOPS”。
推理应用驱动的并发I/O操作,可能比传统基于CPU的应用高出数百甚至数千倍。
AI基础设施的大部分成本实际上用于推理阶段。
这显示出推理已成为AI基础设施的真正瓶颈。
生成式AI进入多模态融合阶段,进一步加剧了这一挑战。
AI应用核心已从专注于文字的LLM扩展到声音、视觉与动态内容。
当AI从纯文字转向多模态,每个视频帧或3D场景所需的Token数量远超文字,导致日均Token消耗量暴增数十倍。
应对方案
为应对推理需求,半导体厂商开始推出专门解决方案,从“算力竞赛”转向“总拥有成本”优化。
英伟达的Rubin CPU芯片,就是为处理长上下文视频与代码任务设计的专用芯片。
值得注意的是,该芯片采用成本效益更高的GDDR7,而非HBM,在容量、带宽与成本间取得了更好平衡。
此外,推理阶段可以通过量化技术降低存储压力,使用INT8、FP8甚至4-bit量化,大幅减少内存占用与带宽需求。
例如通过量化优化后,原本需要16位精度的70亿参数模型,可以压缩到4位并在8GB GPU上运行推理。
如何解决AI需求
随着AI模型规模日益庞大,现有存储解决方案面临挑战。
HBM虽带宽极高但容量有限,eSSD虽容量巨大但带宽与延迟不足。
AI推理对高IOPS的需求,使得存储系统必须跟上运算速度。
eSSD
在AI服务器数据处理中,对高IOPS的追求使得企业级固态硬盘正加速取代传统硬盘。
尽管eSSD单位成本较高,但随着QLC技术进步,每GB成本大幅降低。
云服务供应商正积极规划在2026年大规模以eSSD取代HDD,这引发了大容量QLC SSD需求暴增。
高带宽闪存
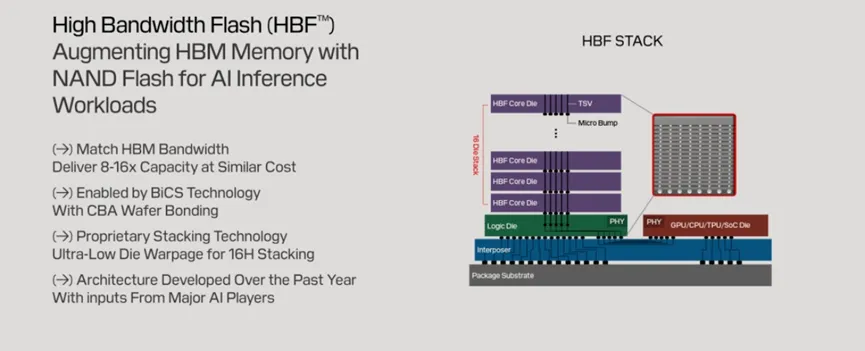
为解决HBM与eSSD之间的鸿沟,闪迪与SK海力士合作推出高带宽闪存(HBF)。
HBF通过将NAND芯片进行3D堆叠,并通过硅穿孔直接与GPU连接,带宽可媲美HBM,容量却是HBM的8至16倍。
边缘AI
AI对存储的影响不仅局限于云端数据中心。
随着AI技术推向AI耳机、AI眼镜和AI PC等终端设备,边缘计算的重要性日益凸显。
在这些边缘AI应用中,NOR Flash因优异的随机存取能力和快速读取速度,成为理想选择。
未来布局
AI推理需求的爆炸性增长,正以前所未有的速度吞噬存储产能,导致DRAM与NAND闪存市场供需失衡。
多家机构预测,在AI需求强劲支撑下,全球关键存储将在2026年面临供不应求。
各家厂商正在多路探索HBM之外的替代技术,平衡性能、功耗与成本。
三星宣布重启Z-NAND;NEO Semiconductor推出X-HBM架构;SanDisk与SK海力士合作开发HBF。
这些方案各自强调带宽突破、能效优化或成本降低,代表着业界正积极探索多元化的技术路线。
未来AI存储的发展将围绕分层存储架构:
由HBM作为高速缓存层、HBF作为大容量模型存储层,以及eSSD作为底层数据湖的新型体系正在形成。
AI推理对IOPS的极高要求,已将存储系统提升至基础设施的核心地位。
这场计算与存储的硬件革新才刚刚开始。
能够洞察并布局的企业,将在AI新纪元中占据领先地位。
点击此处关注,获取最新资讯!




















18126200184































我的评论
最新评论