据闪德资讯获悉,ChatGPT为代表的生成式AI的兴起,为计算行业带来了巨大的变革。
生成式人工智能催生了对计算资源的全新、大规模需求,因为更多的计算资源和数据与性能提升直接相关。
这种新的计算资源需求的核心是擅长并行分布式处理和矩阵运算的图形处理器(GPU)。
过去几年,我们亲身经历了GPU产能问题对整个行业的影响。
AI基础设施变革,或许可以理解为计算能力的中心从传统处理器向GPU的转移,但实际上,一场更根本的变革正在发生。
随着GPU在系统中地位的转变,构成系统本身的核心组件的连接方式也在发生变化。
在此过程中,新的存储技术以及连接这些组件的技术大量涌现,挑战现有架构难以完成的大规模任务。
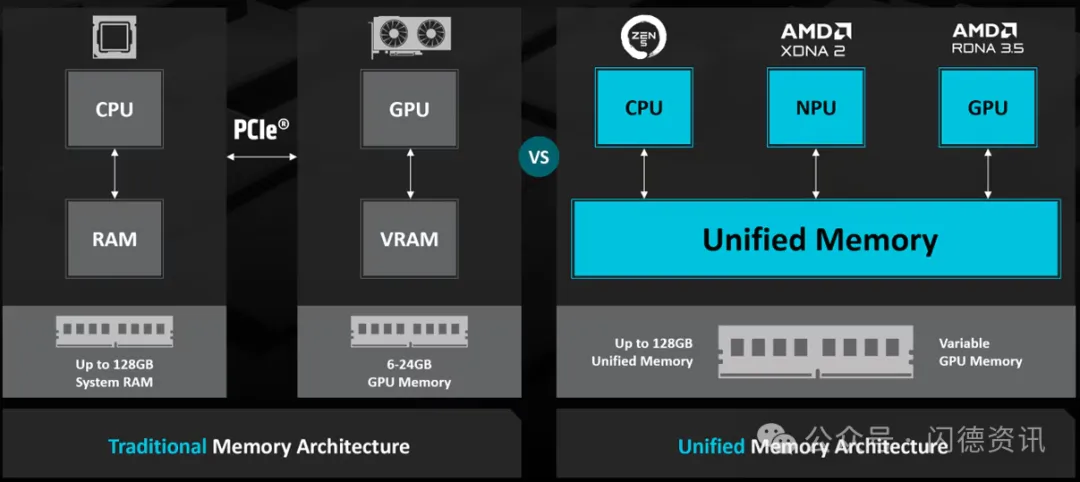
这种时代变迁也体现在最新系统的结构变化中。为了合理利用需要更多内存的大型模型,系统主内存和显存之间的界限(之前是分开的)正在逐渐模糊。
过去由于各种物理限制而难以尝试的“共享集成内存”配置,如今正逐渐成为主流。
这种变化的关键在于如何更高效地获得更大容量的实用内存配置。
GPU内存越来越大、越来越快
近年来,新型GPU的内存容量呈指数级增长。
英伟达数据中心GPU的内存容量几乎每代都翻了一番。
2020年推出的A100拥有40GB内存,2022年推出的H100增加到80GB,2024年推出的H200增加到141GB,B200增加到192GB,2025年发布的B300增加到288GB。
AMD也紧跟趋势,最新的MI350系列中为每个GPU提供288GB内存。
GPU内存逐代大幅提升的原因有很多,但最大的原因是因为必要。
人工智能行业中讨论的“缩放定律”是,随着模型规模的增加,可以实现性能更好、更复杂的模型;处理模型所需的GPU内存需求也会增加。
加载一个具有10亿 (1B) 个参数、32位精度的模型需要4GB的GPU内存,在训练过程中,内存大小需求还会成倍增加。
使用16位精度、4050亿 (405B) 个参数的Rama 3.1模型时,需要810GB的内存,相当于11张H100内存。
这些AI模型对GPU内存的需求在GPU市场中表现出一些显著的特点。
首先,即使是同一款GPU,实际需求也仅限于拥有大内存容量的数据中心GPU。
与加密货币挖矿危机不同,内存容量相对较小、缺乏内存纠错等功能的普通消费级显卡几乎没有受到影响。
这是因为在大型AI研发环境中,普通消费级显卡的效率并不高。配备多个普通消费级GPU时,单个显卡的内存容量较小,限制了安装单元的数量,即使安装多个单元也无法达到最佳效率。
单个GPU的内存容量和性能之所以会产生显著影响,也源于当前系统的结构特性。
目前几乎所有GPU都连接到通用处理器、内存和PCIe(PCI Express)接口,但速度远远不足以支撑内存。
最新标准PCIe 5.0的16通道配置中的最大传输速度约128 GB/s,这与内存的传输性能(从数百GB/s到数TB/s)相差甚远。
因此,当内存不足时,很难考虑使用系统内存,我们面临的情况是需要增加内存来增加模型大小。
另一个值得注意的方面是AI工作负载对内存性能的高度依赖。
通常,当AI模型在GPU上处理数据时,它会从GPU内存中读取大量数据并进行处理。因此,与GPU逻辑核心的实际利用率相比,内存系统的负载非常高。
主要处理AI工作负载的数据中心GPU使用高性能HBM来匹配。
即使是计算性能极其有限的GPU,例如H20,如果内存性能几乎保持不变,能够匹配这些极端工作负载的特性,也能发挥自身的优势。
尽管GPU内存的重要性日益提升,但单纯地增加GPU内存却会带来巨大的负担。
GPU内存从设计阶段就与GPU紧密结合,因此很难仅仅通过增加内存容量来改进GPU内存。如果从设计阶段就大幅增加内存容量,还存在物理制造成本和设计难度等问题。
从产品规划到发布,市场动态在数年间瞬息万变,也会带来巨大的负担。
大容量GPU内存也存在一些问题,因为它不够灵活,无法应对未来的变化。
AI时代的共享内存结构
如果说人们对GPU内存扩展的担忧之一是未来趋势的灵活性,那么共享内存正是解决这一灵活性问题的解决方案。
共享内存结构是指处理器和GPU在逻辑上共享相同的内存硬件,优势在于能够根据需要动态分配内存,从而提高利用效率并最大限度地提高灵活性。
通用处理器和GPU共享同一内存的理念已在客户端使用了数十年。大多数智能手机、平板电脑以及不带独立外部GPU的PC都采用这种结构。
共享内存结构基本上是在同一内存结构中逻辑地划分区域并加以使用,但根据实现方法,也可以从单个池中动态分配。
处理器和GPU可以共享相同的内存区域和数据,这可以大大减轻CPU和GPU之间内存复制和移动的负担。
共享内存结构的弱点是“性能”。
为了使用共享内存结构,处理器和GPU首先必须几乎集成在同一芯片中,但迄今为止,能够组合的CPU和GPU核心数量存在现实的限制。
如果芯片尺寸过大,就会出现功耗、发热量和良率方面的问题;如果芯片尺寸减小,绝对性能又会不足。
物理内存控制器的配置与一般采用“128位宽”配置的外置显卡也存在较大的性能差距,如果控制器配置增加,整个系统配置的复杂性和成本也会大幅增加。
最近一些突破这些限制并使用共享内存结构的产品应运而生。这些产品诞生的背景是半导体工艺和封装技术的进步。
现在,我们可以在承受大型单芯片良率压力的同时,创建相当大的CPU和GPU核心的组合结构,并且将所有芯片单独组合的封装也已成为可能。
随着高速内存标准的使用,内存控制器也已扩展到四通道以上,现在能够为CPU和GPU提供令人满意的性能。
搭载GB10超级芯片的英伟达DGX Spark,以及Strix Halo的AMD Ryzen AI Max系列。
这两款产品的配置和性能特征非常相似。GB10超级芯片搭载20核Arm处理器和基于Blackwell架构的GPU,AI性能可达每秒1千万亿次浮点运算,内存配置为256位宽LPDDR5x内存,性能可达273GB/s。
Ryzen AI Max搭载多达16核Zen 5处理器、40个CU(计算单元)配置的GPU,以及256GB/s带宽和256位宽LPDDR5x内存。
两款产品的GPU理论性能大致相当于中端台式电脑或工作站的GPU,内存带宽也扩展到了中端外置显卡的水平。
最大优势在于,可用的内存容量比性能相当的同级别外置显卡大得多。
AMD“Ryzen AI Max”系列可以将系统内存(最大128GB)中的96GB分配给GPU,但要在外置显卡中获得如此大的容量,需要一块数据中心专用高性能显卡。
这些采用共享内存配置的产品,在AI模型的开发和调整等过程中,有助于提高对大规模模型的可及性。
另一个值得关注的产品是苹果的M3 Ultra芯片。这款芯片也搭载于最新的Mac Studio,据称可提供多达32个CPU核心、80个图形核心、超过800GB/s的内存带宽以及高达512GB的共享内存容量。
如果充分利用,它可以驱动人工智能中6000亿个参数的LLM。
虽然苹果的GPU利用效率尚不确定,但在内存性能和容量方面具有巨大的潜力。
未来,此类集成芯片和共享内存配置,有望成为人工智能工作站或服务基础设施的良好替代方案。
英伟达超级芯片核心是连接内存的互连
在AI基础设施市场最受关注的产品是英伟达超级芯片。
严格来说,超级芯片产品线,例如GH200或GB200,与其说是芯片,不如说更像是模块。
GH200和GB200实际上都是单板模块,通过NVlink连接Grace CPU和Hopper或Blackwell GPU,但它们并没有将所有功能集成到一块芯片中。
虽然理论上,跨越芯片界限存在明显的局限性,但它们目前之所以在市场上备受关注,是因为通过高速NVlink连接最大限度地减少了弱点,并最大限度地发挥了优势。
优势在于,即使使用的内存超过GPU配备的内存,性能影响也微乎其微。
例如GB200在每个GPU上配备192GB HBM3e内存,带宽为8TB/s,在CPU上配备480GB LPDDR5x内存,带宽为512GB/s。并且每个芯片之间的连接通过带宽为900GB/s的NVLink-C2C连接。
到目前为止,几乎所有多芯片解决方案的限制都来自于芯片间连接带宽的不足,但GB200超级芯片的配置使得至少在内存带宽方面,GPU可以直接使用CPU上的内存,性能几乎没有损失。
此外,NVL72通过在机架内直接连接GPU和内存,最大限度地发挥了优势。
即使在使用英伟达GPU的系统中,基于超级芯片系统与普通的DGX、HGX系统之间的差异也由此而来。
DGX系统设计了8个GPU,通过NVLink高速连接,共享彼此的HBM内存空间,但它通过PCIe连接到CPU,因此系统内存的利用并不容易。
这也是为什么许多公司在引入最新GPU服务器时,都考虑采用基于超级芯片的NVL72,而不是现有的基于DGX的系统的原因。
目前,在基于高性能GPU的系统架构中,制约性能的最大因素是PCIe,但还没有好的替代方案。
AMD在Instinct MI300A中引入了一种略有不同的独特系统设计。
MI300系列基于芯片组结构,并将多个组件放置在基座芯片之上。MI300X配置8个GPU芯片,MI300A采用了独特的配置,6个GPU芯片和2个CPU芯片,从而使CPU和GPU在高速结构上共享HBM。
每个芯片提供128GB的HBM3内存,没有单独的外部内存扩展能力,并且通过Infinity Fabric连接4个MI300A在整个系统中共享 512GB内存。
MI300A每芯片提供8个128GB/s Infinity Fabric接口用于外部连接,在4芯片配置中,通常每芯片分配两个接口用于连接每个芯片,另外两个用于PCIe等外部扩展。
虽然与英伟达超级芯片相比,在连接性方面可能略有不足,但在实际使用中也毫不逊色。
这款MI300A也曾用于美国劳伦斯利弗莫尔国家实验室的El Capitan超级计算机,该计算机目前在全球TOP 500超级计算机排行榜中位居第一。
英特尔还在基于第四代至强可扩展处理器Sapphire Rapids的至强CPU Max系列中搭载了HBM。
至强CPU Max系列仅需搭载HBM即可独立运行,与MI300A不同,它可以与现有的DDR5内存配合使用,实现分层内存配置。
通过将高性能HBM和经济实惠的DDR5内存以分层配置的方式用作缓存,还可以提升整体内存性能。
该处理器曾用于美国阿贡国家实验室的超级计算机Aurora,该计算机目前在全球500强超级计算机排行榜中位列第三。
点击此处关注,获取最新资讯!




















18126200184


































我的评论
最新评论