据闪德资讯获悉,Cadence宣布,业内首个LPDDR6/5X内存IP系统解决方案完成流片。
据介绍,该解决方案已经过优化,运行速率高达14.4Gbps,比上一代LPDDR DRAM快50%.
经过扩展之后,AI基础架构可以适应新一代AI LLM、代理AI及其他垂直领域计算密集型工作负载对于内存带宽和容量的需求。
目前公司正在与领先的AI、高性能计算(HPC)和数据中心客户进行多项合作。
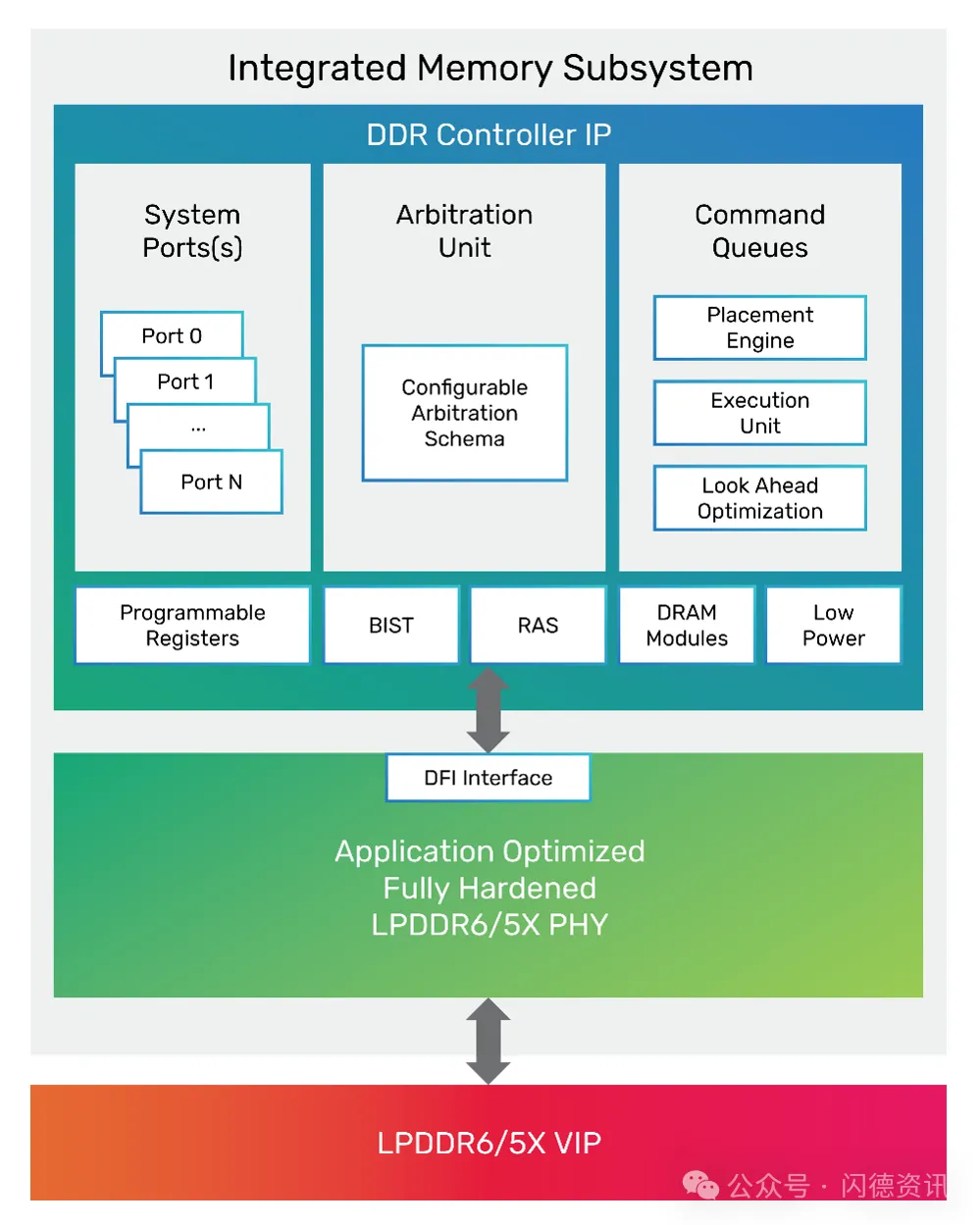
Cadence满足JEDEC LPDDR6/5X标准的IP包括先进的PHY架构和高性能控制器,最大限度地改善功耗、性能和面积(PPA),同时支持LPDDR6和LPDDR5X DRAM协议,以实现更高的灵活性。
该解决方案利用Cadence Chiplet框架,支持原生集成到传统单片SoC和多芯片系统架构中,从而实现异构Chiplet集成。
包含上一代LPDDR的Chiplet框架2024年成功流片。
人工智能的兴起带来了一个悖论:算法日益复杂,但对数据和计算能力的需求却超过了现有基础设施的能力。
Cadence新推出的 LPDDR6/5X 14.4Gbps 内存IP不仅仅是技术升级,更是扩展AI工作负载(从LLM到实时代理系统)的基础赋能器。
通过解决内存带宽和功耗方面的关键瓶颈,正定位为在受人工智能驱动的需求主导的半导体市场中获取溢价。
LPDDR6/5X IP运行速度高达14.4Gbps,比前几代LPDDR5X提升了50%。
像LLM现代AI模型需要大规模并行数据传输才能保持性能。例如,一个1000亿参数模型的单次推理运行可以在几秒钟内消耗数TB的内存。
LPDDR6/5X IP支持双协议(LPDDR6和LPDDR5X),并且功耗比原来的标准降低了50%,成为适用于高端数据中心和边缘设备的多功能解决方案。
该架构的PHY和控制器集成进一步提升了价值。
PHY是一个强化宏,提供与多芯片芯片架构的即插即用兼容性。随着异构芯片(例如GPU+内存+ I/O)成为AI系统的标准,这一点至关重要。
这得益于 Cadence基于UCIe的芯片框架,该框架已在2024年的流片中得到验证。
内存子系统能够根据计算需求无缝扩展,同时最大限度地降低设计复杂性。
预计到2034年,人工智能数据中心市场将以27.1%的复合年增长率增长至1573亿美元,成为这项技术的战场。
LPDDR5X的细分市场正以28%的复合年增长率扩张,这得益于在边缘人工智能设备和高带宽应用中的作用。
Cadence的IP不仅紧跟步伐,更是在跨越式发展。
以500亿美元的AI芯片市场为例:每个为AI设计的GPU、CPU和定制ASIC都需要与计算密度相匹配的内存接口。
Cadence IP现已成为14.4Gbps吞吐量的黄金标准,对于像英伟达、AMD或正在构建AI加速器的初创公司。
随着基于chiplet的设计(例如英特尔的Foveros或AMD的3D V-Cache)成为主流,Cadence的生态系统优势(涵盖设计工具、验证模型和 IP 兼容性)将拓宽护城河。
价值23亿美元的内存IP市场正在围绕参与者进行整合。
Cadence的14.4Gbps IP现已成为任何下一代AI芯片设计的必备条件,而被数据中心巨头(例如微软的Azure或谷歌云)率先采用,标志着拥有先发优势。
同时,到2030年, AI云基础设施的支出将达到450亿美元,这确保了对IP许可和支持的持续需求。
点击此处关注,获取最新资讯!




















18126200184





























我的评论
最新评论